This is a continued topic on Naïve Bayes for Categorical Attributes. Naïve Bayes works easily with categorical attributes by counting how often each value occurs for each class. But when the attribute is numeric (e.g., temperature = 66), you can’t count exact matches, because:
- A numeric value may be unique in the dataset
- The probability of any exact real number (like exactly 66) is effectively zero
So instead of using counts, we model the distribution of numeric values using probability density function (PDF).
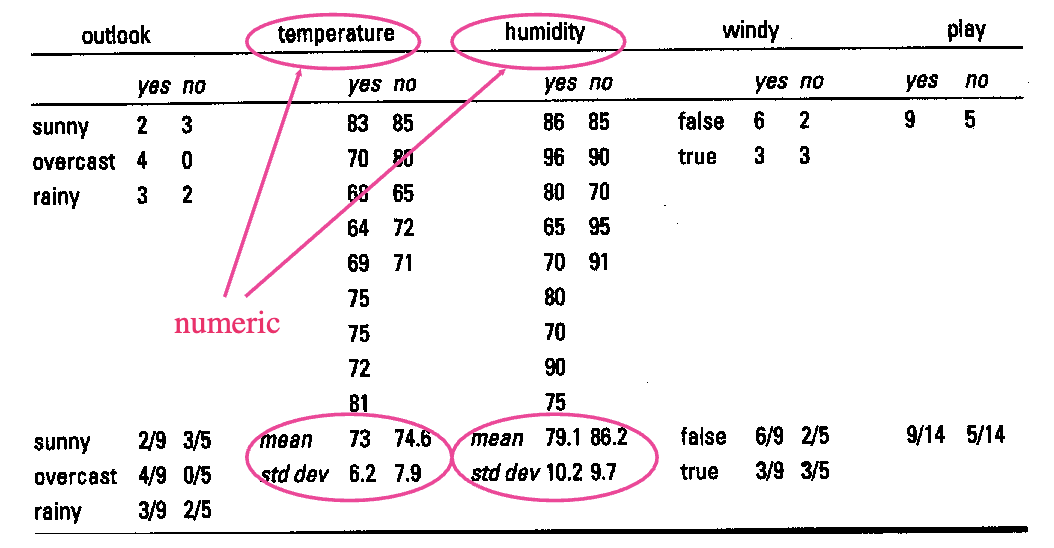 We would like to classify the following new example:
We would like to classify the following new example:
outlook=sunny, temperature=66, humidity=90, windy=true
How to calculate
, ; and
,
Using a PDF (Typically Gaussian)
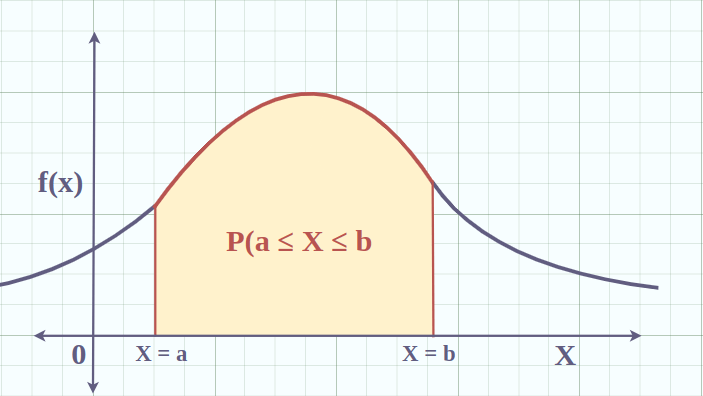
A Probability Density Function (PDF) describes how likely a continuous random variable is to take on a particular range of values.
Unlike categorical variables (which have probabilities like “3/10 chance of rain”), continuous variables (like temperature, height, weight) don’t have probabilities for exact values — because the probability of any single point is zero (e.g. 66.000000…).
Instead, we use the PDF to say:
- How dense the probability is near a value (e.g., around 66)
- The area under the curve between two values (like 65.5 and 66.5) gives the actual probability
Assumption We assume the numeric attribute values follow a normal (Gaussian) distribution for each class.
For a normal distribution with mean and standard deviation , the probability density function is:
- = the numeric value you’re evaluating (e.g., 66)
Calculating probabilities using PDF
Given the example:
outlook=sunny, temperature=66, humidity=90, windy=true.
We want to find and . Recall the Bayes Theorem: and we split the evidence into 4 smaller pieces of evidence using the Naive Bayes’s independence assumption: We already known from the Example - Weather that:
We are now to find:
Solve for
We know from the training data:
- Mean () for
tempforclass=yes= 73 - Standard deviation () for
tempforclass=yes= 6.2
Now we can calculate using the PDF:
Solve for
Similarly we can solve using the same steps.
Compare and
We substitute the values we obtained to the equations:
Similarly, solve for :
We can conclude that: Since: For the new day play = no is more likely than play = yes.
Back to parent page: Supervised Machine Learning
AI Machine_Learning COMP3308 Unsupervised_Learning Eager_Learning Classification Naïve_Bayes Continuous_Attributes Probability_Density_Function