Related algorithm:
Algorithm Algorithm_Paradigm Divide_and_Conquer Recurrence_Relation Unrolling Master_Theorem Merge_Sort
Divide and conquer algorithm is a fundamental algorithm paradigm in computer programming to solve complex problems by breaking them down into smaller sub-problems. Most of the time, adopting divide and conquer algorithm results in better time efficiency compared to other direct solving or brute force algorithms.
The approach
The idea of divide and conquer is to divide, conquer, and combine, or in other textbooks you may see divide, recur and conquer. When you have a problem , you break it down into subproblems , , , …, , you apply the algorithm recursively on each subproblem until each subproblem is small enough to be solved directly. Once each problem has been solved, you merge the solutions of the subproblems to obtain the solution for the original problem . The key aspect here is the algorithm that works on the original problem , must also work on the subproblems; and the solutions of subproblems can be merged to obtain the solution to the problem .
Merge sort example
The Merge Sort algorithm recursively divide the original array (original problem) into two sub-arrays (subproblems) until the subarray has only one element (can be directly solved).
Merge the ordered sub-arrays to obtain an ordered original array.
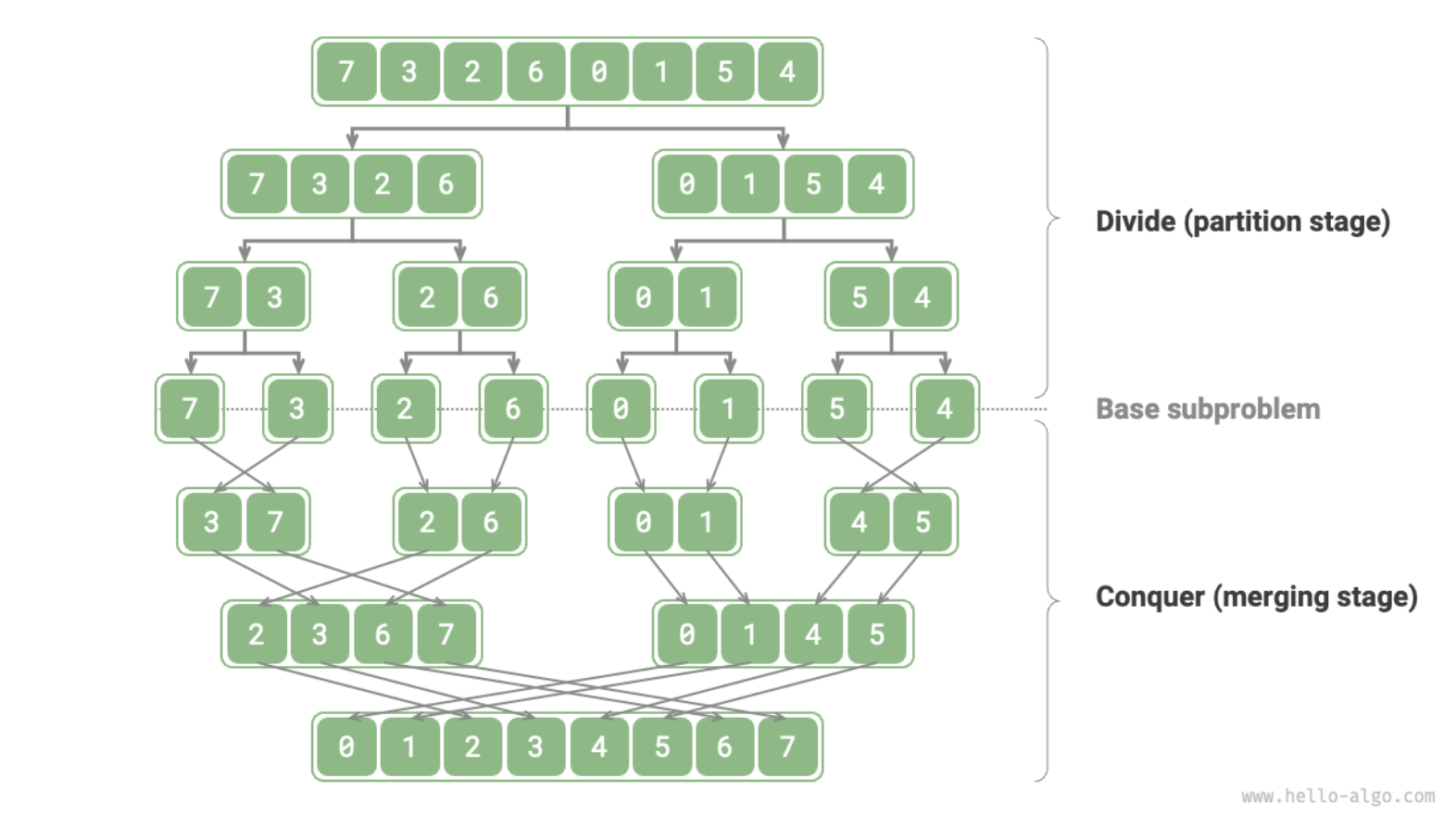 If we evenly divide the original array into multiple sub-arrays, this situation is very similar to bucket sort, which is very efficient in sorting massive data.
If we evenly divide the original array into multiple sub-arrays, this situation is very similar to bucket sort, which is very efficient in sorting massive data.
Performance optimisation
The subproblems produced in divide and conquer algorithm are independent of each other, thus they can usually be solved in parallel. Parallel optimisation is specially effective in environment with multiple cores or processes, the operating system can process multiple subproblems simultaneously, maximise the computing resources for the problem solving, significantly reduce overall runtime. The parallel optimisation is used in bucket sort.
Recurrence relation
A recurrence relation in divide and conquer is an equation expresses the time complexity of the algorithm in terms of the size of the input. The recurrence relation discussed in this chapter is the uniformed recurrence, which the original problem is divided into equal size subproblems.
Let the be the running time, size of input , we need to find out the time cost of:
- Divide step in terms of
- Recur step in terms of
- Conquer step in terms of
Master theorem
The general form of the recurrence relation for divide and conquer can be described as: Where:
- is the time complexity of solving problem of size
- is the size of the original problem
- is the number of subproblems divided from a problem, assume
- is the size of the subproblems (in uniformed recurrence, all subproblems are of the same size, ), assume
- represents the cost outside the recursive calls, also known as the “combine” step.
The master theorem helps determine whether the non-recursive work grows slower, at same rate, or faster than the work done in recursive calls, to justify which dominates the overall runtime.
Complexity analysis
In below the represents the rate of growth of the non-recursive part . The time complexity of non-recursive part can be described as and the time complexity for recursive calls can be described as . The term can be expressed as according to the logarithm rules, it tells the rate at which the number of subproblems grows relative to the size reduction of each subproblem , it essentially tells how the work done by the recursive calls scales.
Now we structure the known information:
- Time complexity
- non-recursive part :
- recursive part :
- Growth rate
- non-recursive part :
- recursive part :
We compare the growth rate of non-recursive part to recursive part to determine which part dominates the overall runtime. Which is, compare to .
Case 1: where
In this case, the cost out side the recursive calls (non-recursive part) grows more slowly than the work done within the recursive calls, the time complexity is dominated by the recursive calls. The solution to the recurrence is dominated by the cost of solving the subproblems (divide and conquer steps).
Case 2: where
Here, the cost outside the recursive calls grows at the same rate as the work done within the recursive calls. Since the growth rates are identical, the solution can be written in terms of : Or, in terms : The extra factor comes from the depth of the recursion tree. Different from case 1 and the later case 3, the cost of combine step grows at the same rate as the cost of recursive calls. This balance means that each level of the recursion contributes equally to the total complexity. Unlike, case 1 and case 3, either recursive calls or combine step dominates the overall runtime.
Case 3: where
In this scenario, the cost outside the recursive calls grows faster than the work done within the recursive calls. The solution to the recurrence is dominated by the cost of combine step, given that for some and sufficiently large . The factor is to ensure that, the cost of solving the subproblems is aways less than a fraction of the cost of combining the solutions.
Here are some examples on solving recurrence relations using master theorem.
Unrolling
Unrolling is another method for time complexity analysis for divide and conquer problems, it repeatedly expand recurrence until reaches the base case, to discover a pattern. Steps in the unrolling method:
- Start with the given recurrence relation
- Substitute the relation iteratively
- Identify the pattern
- Sum the identified pattern to obtain a general form
- Incorporate the base case to finalise the solution
Here are examples about complexity analysis using unrolling.
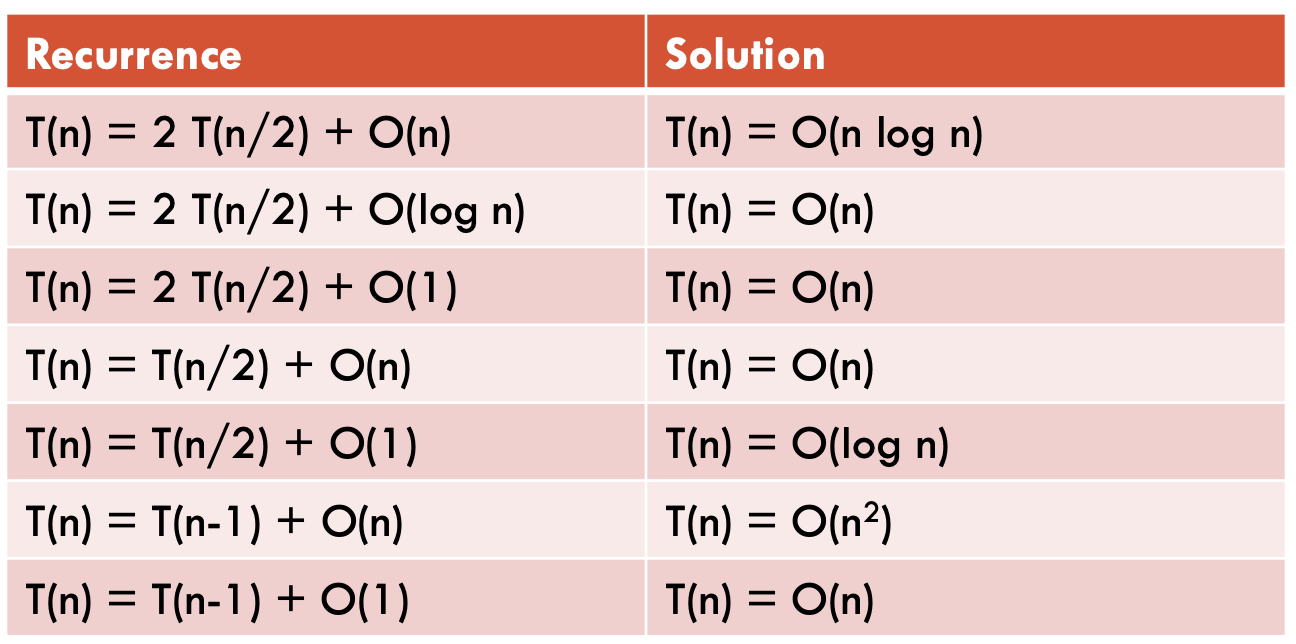
Recurrence relation cheat sheet
Back to parent page: Data Structures and Algorithms