Abstract data type:
Data_Structure Map Hash_Table Open_Addressing Separate_Chaining Linear_Probing Cuckoo_Hashing
A hash table, also known as hash map, is a map data structure that can map key to values. It uses hash function to compute an index into buckets or slots, from which the desired value can be found in .
This page discusses the implementation of hash tables, and the approaches to address hash collisions including separate chaining, open addressing and other resolutions.
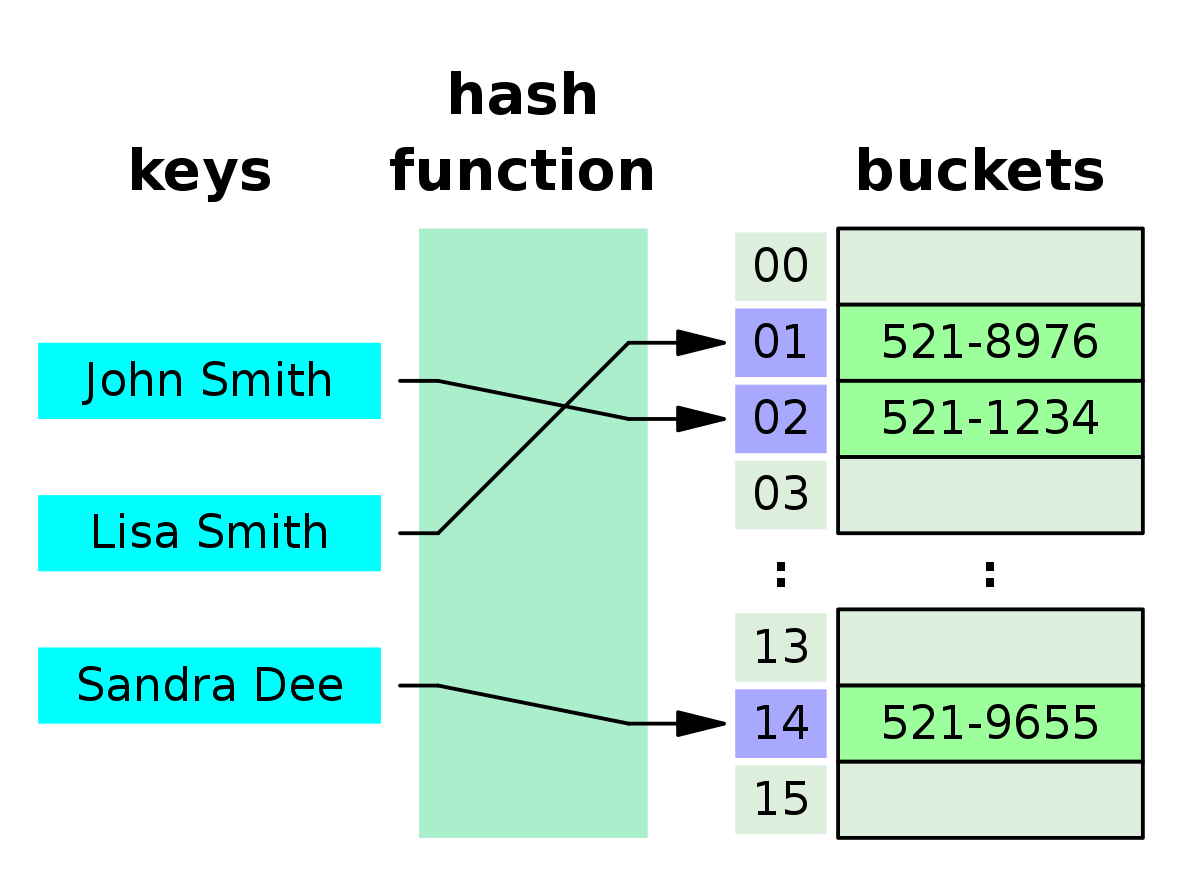
Properties
- Stores key-value pairs
- Constant average case lookup time, makes them very efficient for retrieving data
- Constant time for average case insertion and deletion
- Hash table uses hash function to compute hash codes for keys
Terminologies
- Key
- In hash table, a key refers to a unique identifier associated with a value. It can be used to retrieve the corresponding value. In hash table, a key can be a integer, string, attribute of an object, etc.
- Hash function
- A hash function is used to map keys into indices in the hash table’s underlying array.
- Hash value
- A hash value is produced by the hash function for a given key. Hash value are used to calculate the index where the corresponding value will be stored in the array.
- Bucket
- Each element in the underlying array is a bucket, a bucket is usually a list or container where key-value pairs are stored. Each bucket corresponds to an index in the array.
- Load factor
- The ratio of the number of stored elements to the total number of buckets in the hash table. It can be described as .
Pros and cons
- Advantage
- Fast lookup: Hash table provides fast lookup times for elements, often . Because it uses hash function to map keys to array indices.
- Fast insertion and deletion: In general, hash table provides constant time for insertion and deletion in average case.
- Flexible key types: Hash tables can handle various key types, including integer, string, even custom objects, the hash function typically combines the hash codes of the object’s attributes or fields.
- Disadvantage
- Collision resolution: Hash collision can happen when two distinct keys hash to the same index. Resolving collision requires additional processing (chaining, open addressing), which can impact the performance.
- Memory overhead: Hash tables may create memory overhead especially when the load factor is high.
- Not rated for ordered operations: Hash tables do not maintain any inherent order among elements.
Hash function
Hash table is often based on array, each empty slot in the array is called a “bucket”, each bucket can store on key-value pair. Therefore, the query operation involves finding the bucket corresponding to the key and retrieve the value from it.
How do we locate a appropriate bucket based on key? This is achieved through a hash function. A hash function is used to map keys into indices in the array.
Hash by division is one of the hashing approaches, it involves two steps:
- Calculate the hash value for a key using a certain hash algorithm
hash() - Take the modulus (%) of the hash value with the number of buckets (array length)
capacityto obtain the array indexindex.
index = hash(key) % capacity
Afterwards, we can use the index to access the corresponding bucket in the hash table to retrieve the value.
Implementation
In this simple implementation, we use integer as the key.
class Pair {
public int key;
public String;
public Pair(int key, String val) {
this.key = key;
this.val = val;
}
}
public class ArrayHashMap {
// each buck stores a key-value pair
private List<Pair> buckets;
public ArrayHashMap() {
buckets = new ArrayList<>();
// initiate 100 buckets, adjust the number as needed to avoid frequent resizing
for (int i=0; i<100; i++) {
buckets.add(null);
}
}
private int hashFunc(int key) {
int index = key % 100;
return index;
}
public String get(int key) {
int index = hashFunc(key);
Pair pair = buckets.get(index);
if(pair == null) {
return null;
}
return pair.val;
}
public void put(int key, String val) {
Pair pair = new Pair(key, val);
int index = hashFunc(key);
buckets.set(index, pair);
}Hash collision
A hash collision occur when two or more distinct keys hash to the same index.
The role of hash function is to map the input key to an output index where index has to be in bound of the size of the buckets. However, input size often greater than the size of the buckets; therefore, there must be situation where multiple inputs correspond to the same output, where there must be some same key values.
In the above hash function hashFunc(), if there are two input key are the same, the two output hash values or the indices will also be the same.
For example, we are storing key pairs where the key is the student ID, and the val is the student name. Now we have two students with ID 12836 and 20336.
We calcuate the hash value for both students:
12836 % 100 = 36
20336 % 100 = 36
Both students with different ID points to the same hash value, and when we store them into the hash table, the first student who stored in this bucket will be overrode.
Resolve hash collision
Resolve hash collision is to allow hash table still perform its desired functions and produce output as expected in the event of hash collision. The two methods usually adopted for such resolution are “Separate Chaining” and “Open Addressing”.
Increase capacity
One way to mitigate the hash collision is to increase the capacity of the hash table, the larger the hash table, the less probability of hash collision. In the above example, if we increase the capacity of the hash table to 200, the hash function will return two different hash values, which resolves the conflict.
Capacity increased to 200:
12836 % 200 = 36
20336 % 200 = 136
Separate chaining
The original hash table, each bucket can store one key-value pair. In separated chaining, each buck points to a linked list, which can store multiple pairs. All colliding pairs are stored into a linked list.
 In this example, if value
In this example, if value 10 and 70 having the same key, they are stored into a linked list.
Limitations
- Increased space usage
- The extra linked list contains pointers, which consumes more memory.
- Reduced query efficiency
- The linear traversal to find the target pair in linked list requires extra time.
Operations
- Querying element
- When querying an element, if the hash value (
index) for querying maps to a bucket with multiple pairs, the algorithm traverses the linked list and compares key to find the target key-value pair.
- When querying an element, if the hash value (
- Adding element
- Calculate the index from the key, the new element is appended to the linked list of the calculated bucket position.
- Deleting element
- Locate the bucket, access the head of the linked list and travers the linked list to find the target node, delete the node with linked list delete operation.
Implementation
The implementation contains resize operation, when load factor exceeds , the hash table is expanded to twice of its original size.
class HashMapChaining {
int size; // number of stored key-value pairs
int capacity;
double loadThres; // load factor threshold for triggering expansion
int extendRatio; // expansion multiplier
List<List<Pair>> buckets; // bucket array
public HashMapChaining() {
size = 0;
capacity = 4; // initial capacity is 4 buckets
loadThres = 2.0 / 3.0;
extendRatio = 2; // the capacity is doubled when expanded
buckets = new ArrayList<>(capacity);
// array based list
for (int i = 0; i < capacity; i++) {
buckets.add(new ArrayList<>());
}
}
int hashFunc(int key) {
return key % capacity;
}
double loadFactor() {
return (double) size / capacity;
}
// query operation
String get(int key) {
int index = hashFunc(key);
List<Pair> bucket = buckets.get(index);
// traverse the bucket, compare the key to find target pair
for (Pair pair : bucket) {
if (pair.key == key) {
return pair.val;
}
}
// if key is not found, return null
return null;
}
// add operation
void put(int key, String val) {
// when the load factor exceeds the threshold, perform expansion
if (loadFactor() > loadThres) {
extend();
}
int index = hashFunc(key);
List<Pair> bucket = buckets.get(index);
// traverse the bucket, if the specified key is encountered, update the corresponding val and return
for (Pair pair : bucket) {
if (pair.key == key) {
pair.val = val;
return;
}
}
// if the key is not found, append the key-value pair to the end
Pair pair = new Pair(key, val);
bucket.add(pair);
size++;
}
// remove operation
void remove(int key) {
int index = hashFunc(key);
List<Pair> bucket = buckets.get(index);
// traverse the bucket, remove the key-value pair from it
for (Pair pair : bucket) {
if (pair.key == key) {
bucket.remove(pair);
size--;
break;
}
}
}
// expand hash table
void extend() {
// temporarily store the original hash table
List<List<Pair>> bucketsTmp = buckets;
// initialize the extended new hash table
capacity *= extendRatio;
buckets = new ArrayList<>(capacity);
for (int i = 0; i < capacity; i++) {
buckets.add(new ArrayList<>());
}
size = 0;
// move key-value pairs from the original hash table to the new hash table
for (List<Pair> bucket : bucketsTmp) {
for (Pair pair : bucket) {
put(pair.key, pair.val);
}
}
}
// print hash table
void print() {
for (List<Pair> bucket : buckets) {
List<String> res = new ArrayList<>();
for (Pair pair : bucket) {
res.add(pair.key + " -> " + pair.val);
}
System.out.println(res);
}
}
}Time complexity
The average time for hash table operations such as insertion, lookup, and deletion takes . The worst case is where all the items collide into a single chain.
Open addressing
The open addressing is another collision resolution method in hash tables where, instead of storing all colliding pairs to the same index using a linked list (separate chaining), each pair is stored directly in the hash table array. When a collision occurs, the hash table algorithm searches for another position within the array to store the new pair. This process is governed by a probing sequence, which determines the order in which alternative slots are considered.
Linear probing
In linear probing, if a collision occurs, the algorithm linearly travers forward from the conflict position until a vacant slot is found, then the new pair is inserted to that slot. There exists quadratic probing and other probing methods, they employ similar approach but with different step sizes, these methods won’t be discussed here.
The linear probing has the execution sequence:
(hashFunc(x)+0) % capacity
(hashFunc(x)+1) % capacity
(hashFunc(x)+2) % capacity
// ...
// Until an empty slot is found.
Limitations
- Clustering results in degraded performance
- When multiple keys hash to the same index or adjacent indices, they form a cluster. As cluster grows, the probability of additional collisions increases, leading to longer probe sequence and degraded performance.
Operations
- Querying element
- Calculate the index for a given key using hash function, check if the index position contains the target pair. If it contains a different key, linearly probe the array until target pair is found or encounter an empty slot, which indicates item not found.
- Adding element
- Calculate the index for a given key using hash function
- If the index position is empty, insert new pair there
- If the index position has already taken, linearly traverse forward from the conflict position (usually with a step size of 1), until a vacant slot is found, then insert the new pair.
- Deleting element
- Deletion in linear probing is more complex, as it needs to ensure search operation still works correctly after an element is removed. Simply remove an item by setting a slot to empty can break the probing sequence.
- Instead of setting a slot to empty, we employ lazy deletion, mark the pair to delete with a special marker called “TOMBSTONE”. When linear probing encountered a “TOMBSTONE”, it should continue traversing since the target pair may still in place behind the “TOMBSTONE”.
Implementation
The code below implements the open addressing using linear probing with lazy deletion. To better use the hash table space, the implementation uses circular array. When querying an item, if there is a “TOMBSTONE” before the target item during linear probing, the item is moved to the “TOMBSTONE” position, which helps reducing the wasted space and increase the efficiency for the next lookup.
// open addressing using linear probing
class HashMapOpenAddressing {
private int size;
private int capacity = 4;
private final double loadThres = 2.0 / 3.0;
private final int extendRatio = 2;
private Pair[] buckets; // bucket array
private final Pair TOMBSTONE = new Pair(-1, "-1"); // removal mark
public HashMapOpenAddressing() {
size = 0;
buckets = new Pair[capacity];
}
private int hashFunc(int key) {
return key % capacity;
}
private double loadFactor() {
return (double) size / capacity;
}
// search for the bucket index corresponding to key
private int findBucket(int key) {
int index = hashFunc(key);
int firstTombstone = -1;
// linear probing, break when encountering an empty bucket
while (buckets[index] != null) {
// If the key is found
if (buckets[index].key == key) {
// if a removal mark was encountered earlier
// move the key-value pair to that index
if (firstTombstone != -1) {
buckets[firstTombstone] = buckets[index];
buckets[index] = TOMBSTONE;
return firstTombstone; // return the moved bucket index
}
return index; // return bucket index
}
// record the first encountered removal mark
if (firstTombstone == -1 && buckets[index] == TOMBSTONE) {
firstTombstone = index;
}
// linearly probe the array
// calculate the bucket index with 1 step size increment
// return to the head if the array is exhausted (circular)
index = (index + 1) % capacity;
}
// If the key does not exist, return the index of the insertion point
return firstTombstone == -1 ? index : firstTombstone;
}
// Query operation
public String get(int key) {
// search for the bucket index corresponding to key
int index = findBucket(key);
// if the key-value pair is found, return the corresponding val
if (buckets[index] != null && buckets[index] != TOMBSTONE) {
return buckets[index].val;
}
// if the key-value pair does not exist, return null
return null;
}
// add operation
public void put(int key, String val) {
// when the load factor exceeds the threshold, perform expansion
if (loadFactor() > loadThres) {
extend();
}
// search for the bucket index corresponding to key
int index = findBucket(key);
// if the key-value pair is found, overwrite val and return
if (buckets[index] != null && buckets[index] != TOMBSTONE) {
buckets[index].val = val;
return;
}
// if the key-value pair does not exist, add the key-value pair
buckets[index] = new Pair(key, val);
size++;
}
// remove operation
public void remove(int key) {
// search for the bucket index corresponding to key
int index = findBucket(key);
// if the key-value pair is found, mark it as removed
if (buckets[index] != null && buckets[index] != TOMBSTONE) {
buckets[index] = TOMBSTONE;
size--;
}
}
// expand hash table
private void extend() {
// temporarily store the original hash table
Pair[] bucketsTmp = buckets;
// initialize the extended new hash table
capacity *= extendRatio;
buckets = new Pair[capacity];
size = 0;
// move key-value pairs from the original hash table to the new hash table
for (Pair pair : bucketsTmp) {
if (pair != null && pair != TOMBSTONE) {
put(pair.key, pair.val);
}
}
}
// print the hash table
public void print() {
for (Pair pair : buckets) {
if (pair == null) {
System.out.println("null");
} else if (pair == TOMBSTONE) {
System.out.println("TOMBSTONE");
} else {
System.out.println(pair.key + " -> " + pair.val);
}
}
}
}Time complexity
In average case, assume hash values are uniformly random distributed, the load factor is a constant , then the expected running time for common operations is .
Cuckoo hashing
Cuckoo hashing is a technique used to resolve collisions in hash tables by providing a constant lookup time. It achieves this by using multiple hash functions and multiple hash tables (usually 2 hash tables). When a collision occurs during insertion, the conflicting key is moved to another table using a different hash function. In practice Cuckoo hashing is 20-30% slower than linear probing but is still often used due to its worst case guarantees on lookups and its ability to handle removal more gracefully.
Operations
Use two hash tables and , each of size . Use two hash functions and for and respectively. Here we use counter for eviction cycle detection.
- Querying element
- Use the two hash function and to compute the index of the key in the first and the second hash table
- Lookup the computed indices in the and then . If the key is found, return the associated value
- If the key is not found in either hash table, return “key not found”
- Adding element
- Attempt to insert into
- Use the first hash function to calculate the hash index
idx1=h1(key) - Check if the slot at the first hash table is empty:
T_1[idx1] - If it is empty, insert the new item there and return
- If the slot in is occupied, evict the existing item at
idx1, place the new item there. The evicted item will be reallocated
- Use the first hash function to calculate the hash index
- Reallocate evicted item from
- Calculate the hash index for the evicted item using the second hash function :
idx2=h2(pair.key) - Check if the slot at is vacant
- If it is empty, insert the evicted item in and return
- If it is occupied, evict the existing item in and place the new item there
- Calculate the hash index for the evicted item using the second hash function :
- Repeat if necessary
- The evicted item from is now the new item needs to be allocated
- Loop back to step 1 with this new item, and repeat the process
- Maximum relocation
- The loop continues until either the key is inserted successfully without causing further eviction or the number of displacements (eviction counter) reaches
MAX_RELOCATIONS - If the
MAX_RELOCATIONSis reached, it indicates the table may be too full or an eviction cycle is formed, making it impossible to insert the key without endless evictions. In this case, the hash table needs to be resized and the insertion process retired
- The loop continues until either the key is inserted successfully without causing further eviction or the number of displacements (eviction counter) reaches
- Attempt to insert into
- Deleting element
- Use the two hash function and to compute the index of the key in the first and the second hash table
- Lookup the item in both tables using the computed indices, if the item is found by setting the slot to empty, and decrement the size of the hash table.
- In some implementations, if the load factor drops below a certain threshold after deletion, the hash table may be rehashed to reduce the capacity and optimise the space usage
Eviction cycle
Eviction cycles in Cuckoo hashing occur when there is a series of displacements during the insertion process that result in a cycle, preventing successful insertion of a new key without further eviction.
In the below eviction cycle example, if a new item is hashed to the position where the 7 is at, the 7 will be evicted to the position 2 in the second hash table, the 2 will be evicted to 6 in table 1, and 6 will be evicted to 4 in table 2, 4 will be evicted to 7 in table 1…
This create an endless displacement which called an eviction cycle.
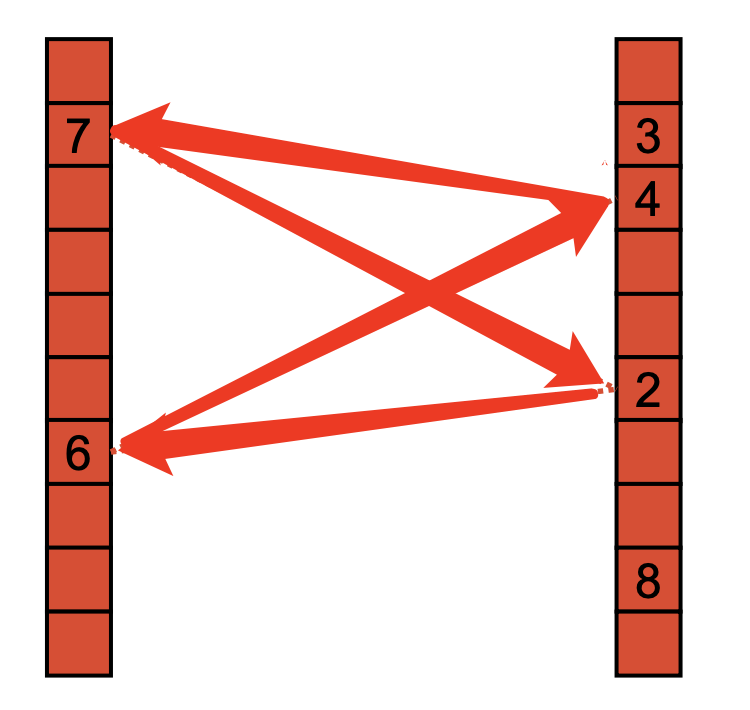
Detect eviction cycle
Counter for evictions
Use a counter to keep track of the number of evictions that occur during the insertion process. Each time an eviction occur, increment the counter. If the counter reaches the threshold MAX_RELOCATIONS, it indicates that an eviction cycle may be present.
If an eviction cycle presents, resizing the hash table and rehashing the keys can help break the cycle.
Flag for items
Maintain an additional flag for each item in the hash table, whenever an item is evicted during the insertion (adding element) process, the flag is set to true. After a successful insertion, unflag all the items that were flagged during the process.
If an entry that is being evicted has its flag already set to true, it indicates that this entry has been displaced previously within the same insertion attempt, suggesting a potential cycle in encountered.
Resize the hash table and rehashing the keys to eliminate the eviction cycle.
Time complexity
In the average case, the cuckoo hashing achieves time complexity for insertion, deletion, and query. In worst case for insertion, if the insertion requires multiple evictions and potentially a rehashing of the entire table if an eviction cycle is encountered, the rehashing involves re-inserting all the keys into a larger table, leading to time complexity for the operation.
Back to parent page: Data Structures and Algorithms