Supervised learning is a type of machine learning where a model is trained on labeled data —meaning each input is paired with the correct output. The model learns by comparing its predictions with the actual answers provided in the training data. Over time, it adjusts itself to minimise errors and improve accuracy. The goal of supervised learning is to make accurate predictions when given new, unseen data. For example, if a model is trained to recognise handwritten digits, it will use what it learned to correctly identify new numbers it hasn’t seen before.
Formal definition
Given: a set of pre-classified (labelled) examples , – input vector, - target output (class) Task: learn a function (classifier, model) which encapsulates the information in these examples (i.e. maps → ) and can be used predictively.
Explanation
Gigen: You have a dataset made up of:
- : input vector — a list of values/features (e.g., a person’s height, weight, age).
- : target output — the correct answer or label for that input (e.g., whether the person is healthy or not).
Each item in the dataset is a pair — think of it as a question () and its correct answer ().
Task: You want to learn a function (called a classifier or model) that:
- Takes as input.
- Predicts as output.
- This function should “understand” or “capture” the patterns in your labelled examples.
Example
Given: a set of pre-labelled examples (training data)
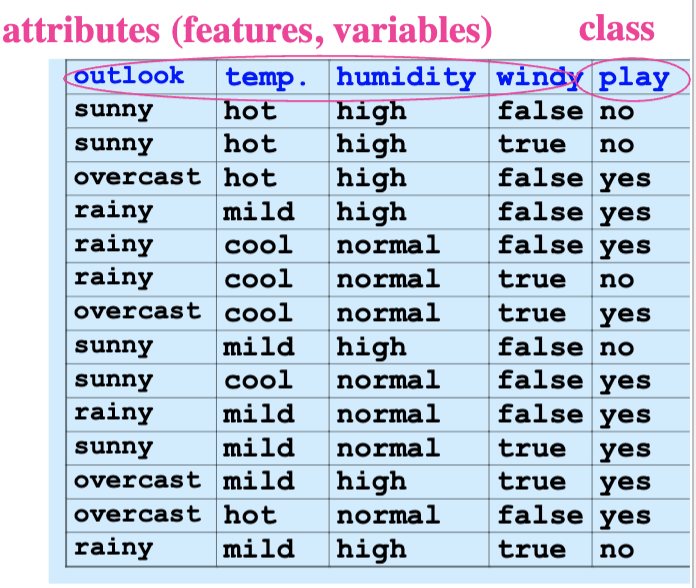
The examples consist of:
- 14 entries
- 4 attributes:
outlook,temp.,humidity,windy - the class is
play(values:yes,no)
Task: build a model (classifier) that can be used to predict the class of new (unseen) examples.
e.g. Predict the class (yes or no) of outlook=sunny, temp=hot, humidity=low, windy=true.
Types of supervised learning
Supervised learning can be applied to two main types of problems:
- Classification
- Where the output is a categorical variable or class (e.g., spam vs. non-spam emails, yes vs. no)
- Regression
- Where the output is a numeric value (e.g., predicting house prices, stock prices)
Supervised machine learning algorithms
Lazy learning
Lazy learning is also called instance-based learning (“lazy” because it waits until the last minute to do the hard work). The algorithms don’t build a model (classifier) from the training data. There is no training phase, instead, it stores the training data (“instances”) and uses them directly to make decisions later. When a new (unseen) example comes in, it compares that example to the stored training data, then classifies it based on the most similar neighbours.
- K-Nearest Neighbour (Classification)
- Weighted Nearest Neighbour
- K-NN Issue - Curse of Dimensionality
Eager learning
The algorithms build a general model (classifier) from training data before seeing new examples. The model is then used to quickly classify new examples.
- 1R Algorithm
- Naive Bayes
Comparison
| Feature | Lazy Learning | Eager Learning |
|---|---|---|
| Training Time | Very fast (just stores data) | Slower (builds a model) |
| Classification Time | Slower (must compare to all data) | Fast (just apply the model) |
| Flexibility | High (adapts to new data easily) | Lower (needs retraining) |
| Memory Usage | High (stores all data) | Lower (just stores the model) |
Back to parent page: Machine Learning (ML)
AI Machine_Learning COMP3308 Unsupervised_Learning Lazy_Learning Eager_Learning